Transcription
Want to make your subtitles look good? Try our new AI-powered alignment and formatting solution
19 Aug 2021
4 minute read
Subtitles are crucial in making media content more accessible and in improving user-friendliness in general. Primarily, it enables people who are deaf or hard-of-hearing to consume the content. Furthermore, it improves comprehension of proper names, foreign words as well as regular speech in the presence of strong accents or background noises. It also enables content creators to expand their reach via translated subtitles. You can read more about the advantages of subtitling here.
Creating subtitles from audio
The creation of subtitles is however not trivial and needs to follow certain rules that improve its readability. There are constraints on the number of characters in a subtitle line, the number of lines in a subtitle frame, the duration of the subtitle frame, and the positioning of line breaks within a subtitle frame.
Subtitle rules can vary between different entities. For example, BBC and Netflix have slightly different guidelines. It is recommended to insert line breaks such that they occur at natural points. For instance, inserting a line break between an article and a noun (e.g., the + book, a + tree) or a pronoun and a verb (e.g., he + runs, they + like playing) hurts the reading flow. Line breaks after punctuation marks such as a comma and a full stop are good since they indicate natural pauses. Therefore, the creation of subtitles involves a careful insertion of line breaks while obeying all the other constraints.

Making subtitles is not always easy
Traditionally, subtitling is done manually by humans. Automatic speech recognition (ASR), which is one of Amberscript’s offerings, assists subtitle creators by automatically converting speech to text. In this case, the mistakes in the ASR transcript are first manually corrected to be perfect. Next, subtitlers use the transcript to generate the subtitles. This process is cumbersome and involves a lot of manual effort trying to conform to the subtitle rules. As a result, subtitling takes a lot more time and costs more money than a simple transcription.
Automatic or manual subtitles from Amberscript
With the growing amount of media content, the demand for subtitling has increased tremendously. At Amberscript, an increase in subtitling jobs means an increase in turnaround times given the limited number of subtitlers. We thus wanted to reduce the human effort in subtitling by automatically formatting subtitles.
While the other rules can be satisfied programmatically, the subtitles rules regarding line breaks indicate that they should rely on linguistic features of the text. Hence, we designed an approach based on deep learning and natural language processing (NLP). We trained models to automatically determine the best position to insert a line break, using high-quality subtitles as training data.
Our models are trained to deliver accurately aligned subtitles in 13 different languages: Dutch, German, English, Swedish, Finnish, Norwegian, Danish, French, Spanish, Italian, Portuguese, Polish, and Romanian. Rather than hard-coding all the rules regarding line breaks, we trained the models to learn to determine when to insert a line break from human-generated subtitles. Our final subtitle formatting algorithm utilizes these models for line breaks while satisfying all the other constraints. The algorithm also runs fast, producing formatted subtitles in just a few seconds for most files. A 12-hour file, for example, requires under two minutes.
Subtitle alignment
An important prerequisite for automatic subtitle formatting is the alignment of speech to the corresponding text. Transcripts from ASR are often edited to add missing words and remove/edit incorrect words. After a transcript is edited and finished, we would need to realign the words to the corresponding speech segments so that the word-level timestamps are accurate. We built an automatic forced alignment algorithm that can perform this step. We currently support forced alignment in three languages – Dutch, German, and English, with more to come in the future.
New workflow for creating subtitles
In order to facilitate the creation of subtitles, we also built a subtitle editor where users can directly edit the formatting of subtitles. When a subtitle job is requested, the ASR first converts speech to text in the form of a transcript. The mistakes in the transcript can be corrected in our transcript editor. Once the transcript is perfected, users can click on the ‘Create Subtitles’ button and set the subtitle rules. The job is then queued for forced alignment followed by subtitle formatting. Once it’s ready, the file can be opened in the subtitle editor, which includes a preview window that shows the subtitles overlayed on the media. Users can adjust the formatting if required and finally export the subtitles in the desired file format.
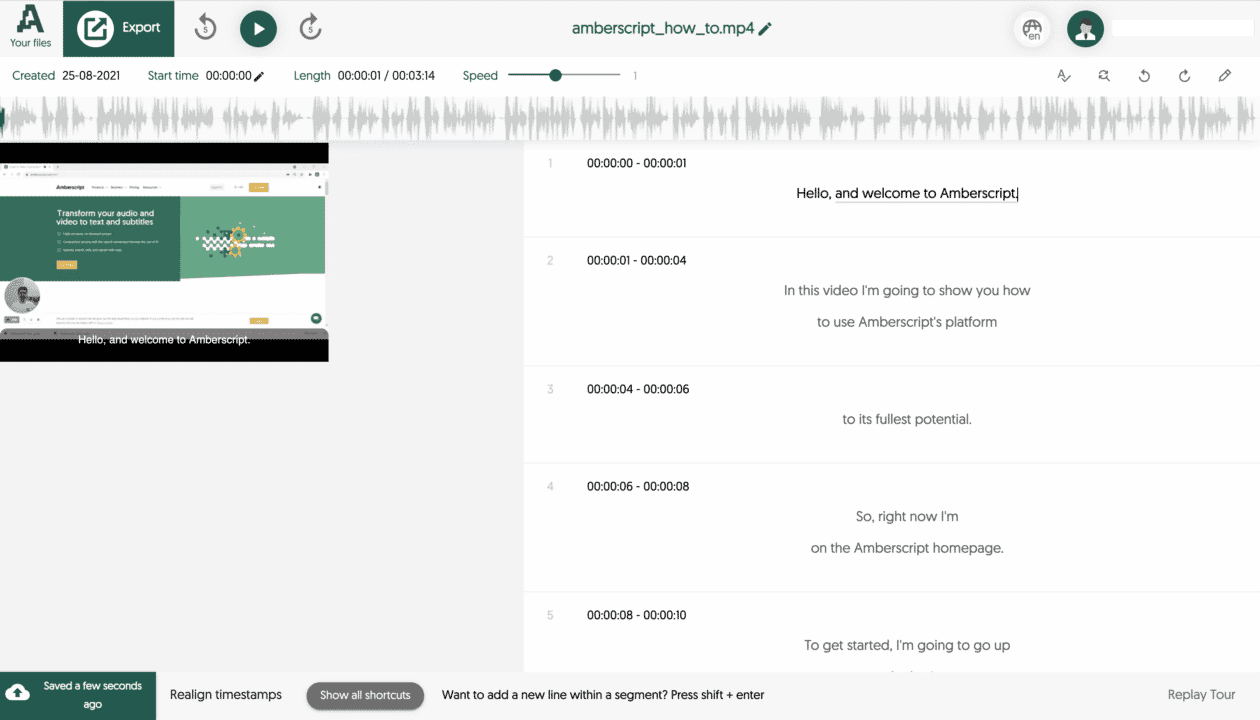
Faster, cheaper subtitles
The combination of ASR and automatic subtitle formatting enables us to offer subtitles much quicker than before. The final result is highly accurate. What’s more – users can decide whether generated subtitles should meet either BBC or Netflix standards.
Additionally, the lower amount of subtitler engagement required means that we can also offer subtitles at a reduced cost. We believe that takes us one step closer to our mission of making all audio accessible.

Add subtitles to your video automatically
- Automatic speech recognition, formatting and alignment saves hours of subtitling time
- Upload, search, edit and export with ease
- Competitive pricing with the fastest turnaround