Media
Wie funktioniert eine Spracherkennungs-Software?
21 Feb. 2020
8 Min. Lesezeit
Mit der Einführung und Etablierung von Smart Home Devices wie Alexa, Cortana, Siri und Google Assistant, hat die Spracherkennung definitiv an neuem Wert gewonnen. Statt Befehle einzutippen, können wir unsere smarten Wohnzimmer-Erfindungen ganz bequem per Sprache steuern.
Inhaltsverzeichnis
- Was ist der aktuelle Stand von Spracherkennung?
- Wie wird Speech-to-Text-Software in verschiedenen Branchen eingesetzt?
- Wie funktioniert ein automatisches Spracherkennungsprogramm?
- Sind alle Spracherkennungstools gleich?
- Was macht Amberscript’s Speech to Text Engine so einzigartig?
- Natürliches Sprachverständnis – Der nächste Meilenstein der Spracherkennung
Was ist der aktuelle Stand von Spracherkennung?
Die Fortschritte im Bereich der Spracherkennung sind beeindruckend und haben unser Leben und unsere Arbeitsweise revolutioniert. Was früher als unmöglich galt, ist heute zur Gewohnheit geworden.
Dank der neuesten Technologien stehen uns heute zahlreiche kostenlose Spracherkennungsprogramme zur Verfügung, die in immer mehr Bereichen eingesetzt werden können. Von der Gesundheitsbranche über den Kundenservice bis hin zur qualitativen Forschung und dem Journalismus – die Umwandlung von gesprochener Sprache in Text hat in all diesen Branchen das Potenzial, den Spielverlauf grundlegend zu verändern.
Warum brauchen wir Speech-to-Text Software?
Sie verkürzt die Zeit für die Transkription von Inhalten
Viele Anwendungsbereiche verlangen qualitativ hochwertige Transkripte. Die Technologie hinter Spracherkennung entwickelt sich rasend schnell und macht es somit schneller, günstiger und bequemer als manuelle Transkription.
Obwohl die Technologie noch nicht and die menschliche Qualität rankommt, kann teilweise eine Genauigkeit von bis zu 95% erreicht werden. Transkription war sonst immer unglaublich zeitaufwendig und arbeitsintensiv, während sich heutzutage die manuelle Arbeit in Grenzen hält und sich auf einige wenige Anpassungen beschränkt.
Software für die Spracherkennung macht Audio zugänglich
Warum erfährt automatische Spracherkennung zurzeit einen derartigen Boom in Europa? Die Antwort ist recht simpel – digitale Barrierefreiheit. Wie die neue EU Richtlinie 2016/2102 besagt, müssen alle öffentlichen Stellen dafür sorgen, dass alle Menschen Zugang zu den bereitgestellten Informationen hat. Für Podcasts, Videos und Tonaufnahmen müssen entweder Untertitel oder Transkripte zur Verfügung gestellt werden, um die Inhalte auch für taube und hörgeschädigte Menschen zugänglich zu machen.
Wie wird Speech-to-Text-Software in verschiedenen Branchen eingesetzt?
Die Technologie der Spracherkennung ist nicht mehr nur eine Annehmlichkeit für den Alltag, sondern wird auch in wichtigen Branchen wie Marketing, Banken und Gesundheitswesen eingesetzt. Spracherkennungsanwendungen verändern die Art und Weise, wie Menschen arbeiten, indem sie einfache Aufgaben effizienter machen und komplexe Aufgaben ermöglichen.
Analyse von Kundenanrufen
Die automatische Transkription hilft Ihnen, Kundengespräche zu verstehen, sodass Sie bei Bedarf die Kundenbetreuung optimieren können. Dieser Service macht auch Ihr Kundendienstteam produktiver.
Untertitelung von Medien und Sendungen
Software zur Umwandlung von Sprache in Text hilft bei der Erstellung von Untertiteln für Videos, damit diese auch von gehörlosen oder schwerhörigen Menschen angesehen werden können. Durch das Hinzufügen von Untertiteln zu Videos werden diese einem breiteren Publikum zugänglich gemacht.
Gesundheitswesen
Mit der Transkription können medizinische Fachkräfte klinische Gespräche in elektronischen Krankenakten aufzeichnen, um sie schnell und einfach zu analysieren. Im Gesundheitswesen trägt dieses Verfahren auch zur Effizienzsteigerung bei, da es einen sofortigen Zugriff auf Informationen und die Eingabe von Daten ermöglicht.
Recht
Speech-to-Text-Software hilft bei der juristischen Transkription, d. h. beim automatischen Schreiben oder Abtippen von oft langen juristischen Dokumenten aus einer Audio- und/oder Videoaufnahme. Dabei werden die aufgezeichneten Informationen in ein schriftliches Format umgewandelt, das leicht zu handhaben ist.
Bildung
Die Verwendung von Sprache in Text kann für Student:innen eine vorteilhafte Möglichkeit sein, Notizen zu machen und mit ihren Vorlesungen zu interagieren. Durch die Möglichkeit, wichtige Teile der Vorlesung hervorzuheben und zu unterstreichen, können sie die Informationen vor Prüfungen leicht noch einmal durchgehen und wiederholen. Auch gehörlose oder schwerhörige Studierende finden diese Software hilfreich, da sie Online-Kurse oder -Seminare untertitelt.
Wie funktioniert ein automatisches Spracherkennungsprogramm?
Das akustische und linguistische Modell
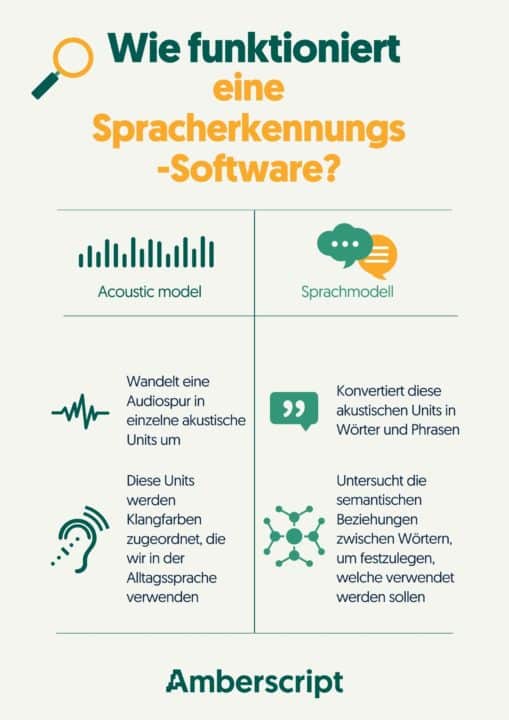
Der Kern der automatischen Transkription ist die automatische Spracherkennungssoftware. Ganz grob gesagt, bestehen solche Systeme aus akustischen und linguistischen Komponenten, die entweder auf einem oder mehreren Computern laufen.
Die akustische Komponente ist dafür verantwortlich, die Audiospur einer Datei in eine Sequenz von akustischen Einheiten umzuwandeln – ganz viele kleine Tonspuren. Hast du schonmal eine Klangwelle „gesehen“? Diese Wellen entstehen durch analogen Ton oder Vibrationen, die beim Sprechen erzeugt werden – welche dann in digitale Signale umgewandelt werden, sodass sie von der Software analysiert werden können. Danach werden die akustischen Einheiten zu bereits existierenden „Phonemen“ zusammengefügt – das sind die Töne, die wir dazu benutzen, um uns mit unserer Sprache auszudrücken.
Danach ist die linguistische Komponente dafür verantwortlich, diese Sequenzen aus akustischen Einheiten in Worte und Sätze zu „verwandeln“. Es gibt viele Worte, die ähnlich klingen, aber etwas ganz anderes bedeuten, wie zum Beispiel Schiff und schief.
Die linguistische Komponente analysiert alle vorliegenden Worte und deren Zusammenhang, um die Wahrscheinlichkeit einzuschätzen, welches Wort als nächstes kommen könnte. Bei Expert:innen ist dies unter „Hidden Markov Models‘‘ bekannt, jene weit verbreitet sind und in jeder Spracherkennungssoftware verwendet werden. So kann die Spracherkennung Teile von Sprach- und Wortendungen bestimmen (mit sich unterscheidender Erfolgsquote).
Ein Beispiel
Man kann das auch ganz einfach im echten Leben ausprobieren, dann hinter jeder Sprachanwendung, wie zum Beispiel Google Translate, verstecken sich Sprachmodelle. Man kann einfach irgendein Wort, das mehrere Bedeutungen hat, hineinsprechen und dann einen Zusammenhang angeben (indem man einen Satz bildet) – so erhält man meist eine deutlich genauere Transkription und Übersetzung.
Bis eine automatische Spracherkennung einsatzfähig ist, müssen je nach Anwendungsbereich verschiedene Komponenten trainiert werden. Sowohl der akustische Teil, also wie gesprochen und aufgenommen wird, als auch der linguistische Teil, also was gesagt wird, sind entscheidend für die Genauigkeit und die Qualität des Transkripts.
Hier bei Amberscript entwickeln und verbessern wir unsere akustischen und linguistischen Komponenten immer weiter, um unsere Spracherkennungssoftware so weit wie möglich zu perfektionieren.
Was ist ein sprecherabhängiges Speech-to-Text-Modell?
Es gibt auch noch so etwas wie das „Speaker Model“. Spracherkennungssoftwares können entweder sprecherabhängig oder -unabhängig sein.
Sprecherabhängige Modelle sind auf eine bestimmte Stimme trainiert, wie zum Beispiel die Sprache-zu-Text-Lösung von Dragon. Man kann auch Siri, Google oder Cortana darauf trainieren, nur die eigene Stimme zu erkennen (mit anderen Worten: einen Sprachassistenten sprecherabhängig machen).
Daraus ergibt sich meist eine höhere Genauigkeit für einzelne Anwendungsbereiche, braucht allerdings Zeit bis das Modell die eine spezifische Sprache versteht. Außerdem ist das sprecherabhängige Modell nicht sonderlich felxibel und kann nicht verlässlich in unterschiedlichen Umfeldern oder mit verschiedenen Einstellungen genutzt werden.
Sie haben es wahrscheinlich schon geahnt – sprecherunabhängige Modelle können ohne Training viele verschiedene Stimmen erkennen. Genau diese Art von Modell kommt in der Amberscript Software zum Einsatz.
Sind alle Spracherkennungstools gleich?
Nein! Viele verschiedene Spracherkennungstools dienen ganz unterschiedlichen Zwecken. Manche sind für einfache, repetitive Zwecke entwickelt, andere sind sehr fortschrittlich. Lass uns einen Blick auf die unterschiedlichen Level der Spracherkennung werfen.
1) Hast du jemals eine Servicehotline angerufen und wurdest von einer Computerstimme dazu aufgefordert, deine Handynummer anzugeben? Dahinter steckt das einfachste Spracherkennungstool, das mit Musterabgleichen (pattern-matching) arbeitet aber ein limitiertes Vokabular hat – nichtsdestotrotz erfüllt es seinen Zweck.
2) Das nächste Level der Spracherkennung involviert statistische Analysen und Modelle (wie zum Beispiel Hidden Markov Models) – worauf wir bereits weiter oben eingegangen sind.
3) Das Erkennen von Dialekten und Akzenten. Sprache ist ein komplexes Gebilde, das jeden Menschen ein wenig anders sprechen lässt. Eine Vielzahl von alemannischen Dialekten wie Schweizerdeutsch, österreichisches Deutsch usw. macht das Modell zusätzlich komplex. Das Sammeln verschiedenartiger Daten kann diese Komplexität jedoch erheblich reduzieren.
4) Das ultimative Level der Spracherkennung basiert auf künstlichen neuronalen Netzwerken, kurz KNN, was es ermöglicht dass eine solche Spracherkennung dazu in der Lage ist, stetig zu lernen und sich selber zu optimieren. Googles, Microsofts und auch unsere Spracherkennung basiert auf maschinellem Lernen.
– Homonyme (Teekesselchen) sind Wörter, die sich genau gleich anhören, aber eine ganz unterschiedliche Bedeutung haben und anders geschrieben werden. Um hier das richtige Wort zu treffen, ist es wichtig, den Zusammenhang zu kennen. Trotz modernster Spracherkennungssoftwares die auf künstlicher Intelligenz basieren, ist es dennoch schwierig jeden einzelnen Kontext richtig zu interpretieren.
Was macht Amberscript’s Speech to Text Engine so einzigartig?
Unsere Software erreicht schätzungsweise bis zu 95% Genauigkeit – so eine Qualität gab es bisher noch nicht auf dem niederländischen Markt. Hier erfährst du, woher diese unübertroffene Leistung kommt:
- Softwareentwicklung. Wir sind sehr stolz auf unser Team bestehend aus talentierten und hochqualifizierten Sprachwissenschaftlern, die ein ausgefeiltes Sprachmodell entwickelt haben, das sich immer weiter ausbauen lässt.
- Große Mengen an Trainingsdaten. Sprache-zu-Text-Software basiert auf maschinellem Lernen. Mit anderen Worten – je mehr Daten du dem System zuführst, desto besser wird es! Wir haben Terabytes an Daten gesammelt und zugeführt, um ein solches Qualitätsniveau zu erreichen.
- Ausgewogener Datensatz. Um unseren Algorithmus zu perfektionieren, haben wir verschiedene Arten an Daten verwendet. Unsere Spezialisten haben dafür gesorgt, möglichst heterogene Trainingsdaten zu sammeln und zu verwenden: männliche und weibliche Stimmen, verschiedene Stimmlagen, sowie verschiedene Akzente und Dialekte etc.
- Verschiedene Szenarien. Wir haben unser Modell in den verschiedensten akustischen Umgebungen getestet, um eine verlässliche und stabile Leistung unter unterschiedlichen Aufnahmebedingungen garantieren zu können.

Natürliches Sprachverständnis – Der nächste Meilenstein der Spracherkennung
Lasst uns über den nächsten großen Schritt für die gesamte Industrie sprechen: Natürliches Sprachverständnis (NLU). NLU ist ein Bereich der künstlichen Intelligenz, der erforscht, wie Maschinen menschliche Sprache verstehen und interpretieren kann. Natürliches Sprachverständnis ermöglicht es der Spracherkennung nicht nur, menschliche Sprache zu transkribieren, sondern auch die tatsächliche Bedeutung der Worte zu verstehen. Anders gesagt: Das Hinzufügen von NLU-Algorhythmen zu einer Sprache-zu-Text-Software kommt dem Hinzufügen eines Gehirns gleich.
Die natürliche Spracherkennung steht der größten Herausforderungen der Spracherkennung gegenüber: das Verstehen und Arbeiten mit einzigartigen und unbekannten Kontexten.
Was kann man mit natürlichem Sprachverständnis machen?
- Maschinelle Übersetzung. Diese wird bereits bei Skype genutzt – man kann in einer Sprache sprechen und diese gesprochene Sprache wird dann automatisch in Text auf einer anderen Sprache transkribiert. Das ist wie die nächste Generation von Google Translate. Und alleine diese Funktion hat enormes Potential – man muss sich nur einmal vorstellen, wie viel einfacher es wird, mit Menschen zu kommunizieren, die eine andere Sprache sprechen.
- Zusammenfassungen. Wir leben in einer Welt voller Daten – es grenzt sogar schon fast an einer Reizüberflutung. Man stellt sich vor, man hat immer direkt die Zusammenfassung eines Artikels, eines Essays oder eine Email zur Hand.
- Kategorisierung von Inhalten. Ähnlich wie beim vorherigen Punkt, können Inhalte in verschiedene Themenbereiche und Kategorien eingeordnet werden. Suchmaschinen wie Google oder Youtube nutzen diese Funktion bereits.
- Analyse von Emotionen. Diese Technik zielt auf die Wahrnehmung und Sichtweise von Menschen ab – durch die systematische Analyse von Blogeinträgen, Bewertungen und Tweets. Diese Funktion wird schon von einigen Unternehmen genutzt, vor allem denjenigen, die auf Social Media aktiv sind.
- Plagiatsprüfung. Einfache Plagiatstools können nur prüfen, ob Inhalte abgeschrieben sind oder nicht. Weiter fortgeschrittene Software, wie zum Beispiel Turnitin, kann sogar erkennen, ob der gleiche Inhalt einfach nur umformuliert wurde, was die Plagiatsprüfung um einiges genauer macht.
Status quo: Wo wird NLU heutzutage bereits verwendet?
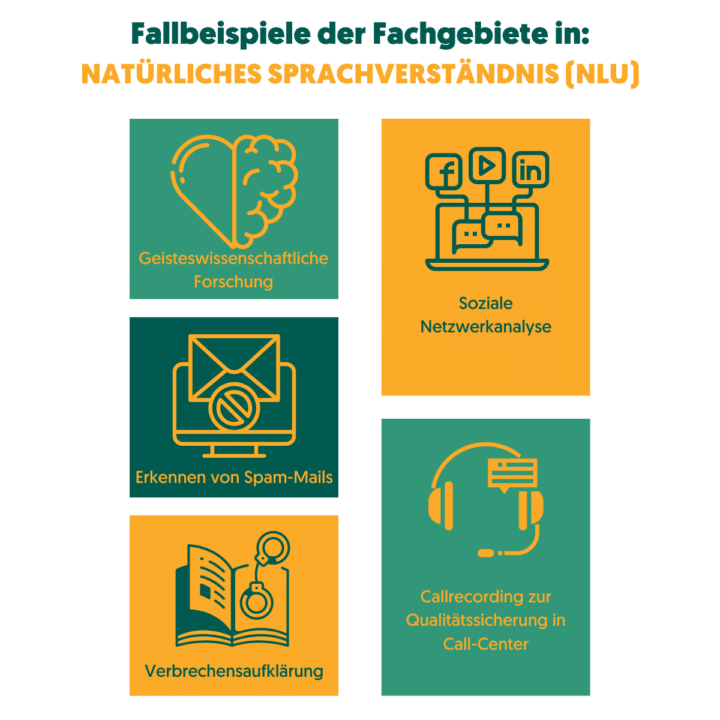
Es gibt viele Bereiche, in denen NLU (als Teildisziplin der natürlichen Sprachverarbeitung) bereits eine große Rolle spielt. Im Folgenden findest du einige Beispiele:
- Social-Media Analyse
- Psychologische Forschung
- Spam-Mail-Erkennung
- Sprachanalyse in Callcentern
- Und sogar…beim Lösen von Verbrechen
Was kommt als nächstes?
Wir arbeiten zurzeit an der Integration von NLU in unser System, um unsere Spracherkennungssoftware noch schlauer zu machen und die Anwendungsbereiche noch mehr auszuweiten.
Wir hoffen, wir konnten die helfen, die faszinierende Welt der Spracherkennung etwas besser kennenzulernen!
Meistgelesen
Barrierefreie Hochschule: Wie Universitäten inklusive und rechtskonforme digitale Lehre umsetzen
9 März 2026
Datenschutz bei Transkriptionssoftware: Darauf sollten Sie achten
23 Feb. 2026
Datensouveränität bei Transkription und Untertitelung: Warum sie für das Risikomanagement Priorität haben muss
23 Feb. 2026