Trascrizioni
Come funziona il software di riconoscimento vocale?
21 Feb 2020
8 minuti di lettura
Lo speech-to-text, chiamato anche riconoscimento vocale, è il processo di sbobinare l’audio in testo quasi in tempo reale.
Lo fa utilizzando algoritmi linguistici per classificare i segnali uditivi e convertirli in parole, che vengono poi visualizzate come caratteri Unicode.
Questi caratteri possono essere consumati, visualizzati e utilizzati da applicazioni, strumenti e dispositivi esterni.
Indice
- Cos’è il software speech to text (parlato-testo)?
- Qual è lo stato attuale del riconoscimento vocale?
- Perché abbiamo bisogno di un software per la conversione del parlato in testo?
- Come viene utilizzato il software speech to text in diversi settori?
- Come funziona il software del riconoscimento vocale?
- Cos’è il modello acustico speech to text?
- Cos’è il modello linguistico speech to text?
- Che cos’è un modello speech to text dipendente dal parlante?
- Cosa rende il software di Amberscript il migliore?
- Comprensione del linguaggio naturale: la prossima grande novità nel settore della comunicazione vocale
Con l’introduzione di software dal parlato al testo come Alexa, Cortana, Siri e Google Assistant, il riconoscimento vocale ha iniziato a sostituire la digitazione, cambiando interamente la modalità di interazione con i nostri dispositivi digitali.
Cos’è il software speech to text (parlato-testo)?
Il software speech to text è utilizzato per tradurre le parole pronunciate in formato scritto. Questo processo è noto anche come riconoscimento vocale o riconoscimento vocale computerizzato. Esistono molte applicazioni, strumenti e dispositivi in grado di trascrivere l’audio in tempo reale per poterlo visualizzare e agire di conseguenza.
Qual è lo stato attuale del riconoscimento vocale?
I recenti sviluppi tecnologici nel campo del riconoscimento vocale non solo hanno reso la nostra vita più comoda e il nostro flusso lavorativo più produttivo, ma hanno anche aperto opportunità che in passato erano considerate “miracolose”.
Il software di riconoscimento vocale ha un’ampia gamma di applicazioni e l’elenco continua a crescere ogni anno. Sanità, miglioramento del servizio clienti, ricerche qualitative, giornalismo: questi sono solo alcuni dei settori in cui la conversione da voce a testo è già diventata una delle principali innovazioni.
Perché abbiamo bisogno di un software per la conversione del parlato in testo?
1. Riduce i tempi di trascrizione dei contenuti
Professionisti, studenti e ricercatori di vari settori utilizzano trascrizioni di alta qualità per svolgere le loro attività lavorative. La tecnologia che sta alla base del riconoscimento vocale progredisce a ritmi sostenuti, rendendola più veloce, economica e comoda rispetto alla trascrizione manuale dei contenuti.
Gli attuali software di speech to text non sono precisi come i trascrittori professionisti, ma a seconda della qualità dell’audio possono raggiungere l’85% di precisione.
2. Il software di riconoscimento vocale rende l’audio accessibile
Perché il riconoscimento vocale sta avendo un grande successo in Europa? La risposta è molto semplice: l’accessibilità digitale. Come descritto nella Direttiva UE 2016/2102, i governi devono adottare misure per garantire a tutti un accesso paritario ai contenuti. Podcast, video e registrazioni audio devono essere corredati di sottotitoli o trascrizioni per essere accessibili alle persone con disabilità uditive.
3. L’ultimo livello di riconoscimento vocale si basa sulle reti neurali artificiali
In sostanza, il motore ha la possibilità di imparare e di auto-migliorarsi. I motori di Google, Microsoft e anche il nostro sono basati sull’apprendimento automatico.

Come viene utilizzato il software speech to text in diversi settori?
La tecnologia speech to text non è più solo una comodità per le persone, ma viene adottata da settori importanti come il marketing, le banche e la sanità. Le applicazioni di riconoscimento vocale stanno cambiando il modo in cui le persone lavorano, rendendo più efficienti i compiti semplici e possibili quelli complessi.
Analisi delle chiamate dell’assistenza clienti
La trascrizione automatica è uno strumento che ti aiuta a comprendere le conversazioni dei clienti, in modo da poter apportare modifiche per migliorare il coinvolgimento dei clienti. Questo servizio rende anche il tuo team di assistenza clienti più produttivo.
Sottotitoli per media e broadcasting
I software di sintesi vocale aiutano a creare sottotitoli per i video e permettono la visione da parte di persone sorde o con problemi di udito. L’aggiunta di sottotitoli ai video li rende accessibili a un pubblico più vasto.

Assistenza sanitaria
Con la trascrizione, i professionisti del settore medico possono registrare le conversazioni cliniche nei sistemi di cartelle cliniche elettroniche per un’analisi rapida e semplice. Nel settore sanitario, questo processo contribuisce a migliorare l’efficienza fornendo un accesso immediato alle informazioni e all’inserimento dei dati.
Trascrizione legale
Il software di trascrizione vocale aiuta nel processo di trascrizione legale, che consiste nella scrittura o nella digitazione automatica di documenti legali spesso lunghi a partire da una registrazione audio e/o video. Ciò comporta la trasformazione delle informazioni registrate in un formato scritto facilmente navigabile.
Istruzione
L’utilizzo della sintesi vocale può essere un modo vantaggioso per gli studenti di prendere appunti e interagire con le lezioni. Grazie alla possibilità di evidenziare e sottolineare le parti importanti della lezione, possono facilmente tornare indietro e rivedere le informazioni prima degli esami. Anche gli studenti non udenti o con problemi di udito trovano utile questo software per interpretare le lezioni o i seminari online.
Come funziona il software del riconoscimento vocale?
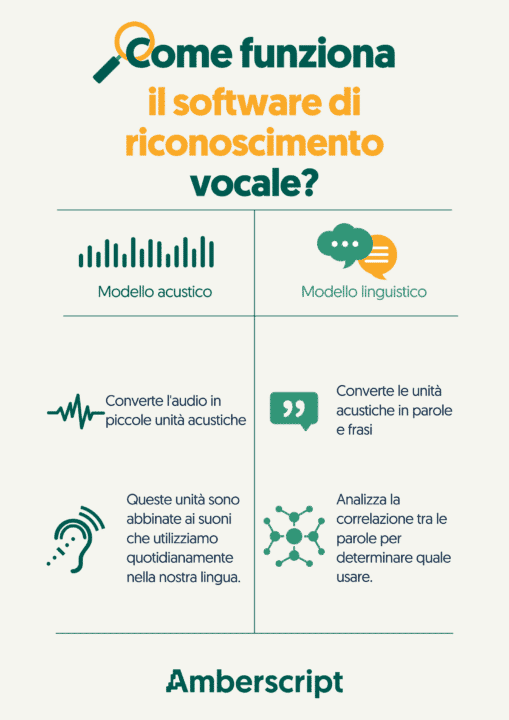
Il fulcro di un servizio speech to text è il sistema di riconoscimento vocale automatico (ASR). I sistemi sono composti da componenti acustici e linguistici che operano su uno o più computer.
Cos’è il modello acustico speech to text?
Il componente acustico è responsabile della conversione dell’audio del tuo file in una sequenza di unità acustiche, ovvero piccolissimi campioni sonori. Hai mai visto una forma d’onda sonora? Si tratta del suono analogico o delle vibrazioni che crei quando parli: vengono convertite in segnali digitali, in modo che il software possa analizzarle. Poi, le unità acustiche citate vengono abbinate ai “fonemi” esistenti (i suoni che utilizziamo nel nostro linguaggio per formare espressioni significative).
Cos’è il modello linguistico speech to text?
Successivamente la componente linguistica è responsabile della conversione di questa sequenza di unità acustiche in parole, frasi e paragrafi. Ci sono molte parole che hanno un suono simile, ma significano cose completamente diverse, come ad esempio pesca (la frutta) e pesca (voce del verbo pescare).
La componente linguistica analizza tutte le parole precedenti e la loro relazione per stimare la probabilità di utilizzare la parola successiva. Gli esperti li chiamano “Modelli di Markov Nascosti” e sono ampiamente utilizzati in tutti i software di riconoscimento vocale. È così che i motori di riconoscimento vocale sono in grado di determinare le parti del discorso e la fine delle parole (con vari successi).
Prova Amberscript gratuitamente
Trascrizione rapida, accurata e sicura con Amberscript
Provalo gratisPrima di poter utilizzare un servizio di trascrizione automatico, questi componenti devono essere istruiti in modo appropriato per comprendere una lingua specifica. Sia la parte acustica del contenuto, cioè il modo in cui viene parlato e registrato, sia la parte linguistica, ciò che viene detto, sono fondamentali per l’accuratezza della trascrizione.
Noi di Amberscript miglioriamo costantemente i nostri componenti acustici e linguistici per perfezionare il nostro motore di riconoscimento vocale.
Che cos’è un modello speech to text dipendente dal parlante?
Esiste anche una cosa chiamata “modello di altoparlante”. Il software di riconoscimento vocale può essere dipendente dal parlante o indipendente dal parlante.
Il modello dipendente dal parlante viene addestrato per una voce particolare, come la soluzione speech-to-text di Dragon. Puoi anche addestrare Siri, Google e Cortana a riconoscere solo la tua voce (in altre parole, rendi l’assistente vocale dipendente dal parlante).
Di solito si ottiene una maggiore precisione per il caso specifico, ma richiede tempo per addestrare il modello a comprendere la tua voce. Inoltre, il modello dipendente dal parlante non è flessibile e non può essere utilizzato in modo affidabile in molti contesti, come nelle conferenze.
Probabilmente hai indovinato: il modello indipendente dal parlante è in grado di riconoscere molte voci diverse senza alcun addestramento. Ecco cosa utilizziamo attualmente nel nostro software di Amberscript.
Cosa rende il software di Amberscript il migliore?

Si stima che il nostro motore di riconoscimento vocale raggiunga un’accuratezza del 95%, un livello di qualità finora sconosciuto al mercato olandese. Saremo più che felici di condividere con te l’origine di queste prestazioni ineguagliabili:
- Architettura e progettazione intelligenti. Siamo orgogliosi di lavorare con un team di logopedisti esperti che hanno sviluppato un modello linguistico sofisticato, aperto a continui miglioramenti.
- Grandi quantità di materiale formativo. Il software di speech-to-text si basa sull’apprendimento automatico. In altre parole, più dati vengono forniti al sistema e migliori sono le sue prestazioni. Abbiamo raccolto milioni di dati per arrivare a un livello di qualità così elevato.
- Dati equilibrati. Per perfezionare il nostro algoritmo, abbiamo utilizzato diversi tipi di dati. I nostri specialisti hanno ottenuto un campione sufficiente per entrambi i sessi, oltre a diversi accenti e toni di voce.
- Esplorazione degli scenari. Abbiamo testato il nostro modello in varie condizioni acustiche per garantire prestazioni stabili in diversi contesti di registrazione.
Rapporto investigativo: Stato dell’accessibilità digitale nell’istruzione universitaria
Tra agosto 2020 e gennaio 2021, Amberscript ha intervistato 350 studenti di 175 università in 15 paesi europei. Scopri come l’accessibilità digitale possa aiutare l’istruzione universitaria.
Comprensione del linguaggio naturale: la prossima grande novità nel settore della comunicazione vocale
Parliamo del prossimo grande passo avanti per l’intero settore: la comprensione del linguaggio naturale (o CLN). Si tratta di una branca dell’intelligenza artificiale che studia in che modo i macchinari possono comprendere e interpretare il linguaggio umano. La comprensione del linguaggio naturale permette alla tecnologia di riconoscimento vocale non solo di trascrivere il linguaggio umano, ma anche di comprenderne il significato. In altre parole, l’aggiunta di algoritmi CLN è simile ad aggiungere un cervello a un convertitore voce-testo.
CLN mira ad affrontare la sfida più difficile del riconoscimento vocale: comprendere e lavorare in un contesto unico.
Cosa si può fare con la comprensione del linguaggio naturale?
- Traduzione automatica. È una funzione già utilizzata da Skype. Parli in una lingua e la tua voce viene automaticamente trascritta in una lingua diversa. Si può considerare come il livello successivo di Google Translate. Già questo ha un enorme potenziale: immagina quanto sarà più facile comunicare con persone che non parlano la tua lingua.
- Riassunto dei documenti. Viviamo in un mondo pieno di dati. Forse ci sono troppe informazioni in giro. Immagina di avere un riassunto istantaneo di un articolo, di un saggio o di una mail.
- Categorizzazione dei contenuti. Come nel caso del punto precedente, i contenuti possono essere suddivisi in temi o argomenti distinti. Questa funzione è già implementata nei motori di ricerca, come Google e YouTube.
- Analisi del sentimento. Questa tecnica mira a identificare le percezioni e le opinioni umane attraverso un’analisi sistematica di blog, recensioni o anche tweet. Questa pratica è già implementata da molte aziende, in particolare da quelle che sono attive sui social media.
- Rilevamento del plagio. I semplici strumenti di plagio verificano solo se un contenuto è una copia diretta. Un software avanzato come Turnitin può già rilevare se lo stesso contenuto è stato parafrasato, rendendo il rilevamento del plagio molto più accurato.
Dove viene applicata la CLN oggigiorno?
Sono molte le discipline in cui la CLN (come suddivisione dell’elaborazione del linguaggio naturale) svolge già un ruolo importante. Ecco alcuni esempi:

Qual è il futuro dell’elaborazione del linguaggio naturale?
Attualmente stiamo integrando gli algoritmi CLN nel nostro software di speech to text per rendere il nostro software di riconoscimento vocale ancora più intelligente e utilizzabile in un’ampia gamma di applicazioni.

Prova Amberscript gratuitamente
Trascrizione rapida, accurata e sicura con Amberscript
Provalo gratisDomande frequenti
-
In che modo il software riconosce i diversi interlocutori e tempi in cui parlano?
Vengono utilizzate diverse tecniche per il riconoscimento degli interlocutori e del tempo, le nostre soluzioni standard includono la diarizzazione del vettore x o la diarizzazione a 2 canali.
-
Che cos’è l’accessibilità web?
L’accessibilità web è l’abilità di un sito web, applicazione per telefono o documento elettronico
di essere facilmente navigato e compreso da un vasto pubblico, inclusi gli udenti
che hanno disabilità visive, uditive, motorie o cognitive. -
Che cosa significa accessibilità web per me?
È sempre importante promuovere l’inclusività nella nostra società, anche se non sei un’istituzione pubblica.
Aiutiamo a garantire che tutti facciano parte della rivoluzione digitale che sta facilitando le nostre vite ogni giorno. Le nostre soluzioni aiutano le persone con disabilità visive, uditive, motorie o cognitive ad accedere allo stesso contenuto. Amberscript fornisce un software con una soluzione: convertiamo file audio e video in testi usando un software di riconoscimento vocale, basato su un sistema di intelligenza artificiale. Per scoprire di più i nostri prodotti, clicca qui. -
In che modo il tema dell’accessibilità web è correlato alla legislazione UE 2016/2102?
Il 22 settembre 2016 l’UE ha pubblicato una direttiva sull’accessibilità web relativa ai siti web delle istituzioni pubbliche. Gli obiettivi inclusi nella direttiva devono essere implementati nella legislazione nazionale di ogni stato membro dell’UE a partire dal 23 settembre 2018. Le istituzioni pubbliche devono conformarsi alla Norma Europea (EN 301 549 V 2.1.2), che si riferisce a un livello “A” o “AA” degli standard internazionali delle Linee guida per l’accessibilità dei contenuti web (WCAG 2.1), come requisiti minimi di accessibilità web. Per saperne di più su questo argomento, leggi il nostro blog sull’accessibilità web e gli standard WCAG 2.1!
-
Che cos’è WCAG 2.1?
WCAG è l’acronimo di Web Content Accessibility Guidelines, ossia le Linee guida per l’Accessibilità dei contenuti sul web. WCAG 2.1 è la versione più recente di queste linee guida, che sono intese per rendere l’ambiente digitale il più accessibile possibile per gli utenti con disabilità visive, uditive, motorie e cognitive.
I più letti
Accessibilità nell’istruzione superiore: come le università possono implementare un apprendimento digitale inclusivo e conforme
10 Mar 2026
Protezione dei dati nei software di trascrizione: cosa devi sapere
23 Feb 2026
Sovranità dei dati nella trascrizione e nella sottotitolazione: una priorità per la gestione del rischio
23 Feb 2026