Transcription
Europe’s trusted partner for secure, high-quality transcription.
Amberscript delivers the most accurate transcripts for your audio or video. Your data remains in the EU, processed according to ISO standards and fully GDPR-compliant.

Loved by brands across Europe




























































Leading the market in secure transcription & subtitles
We prioritize your data security. Our platform is GDPR compliant, ISO 27001 & 9001 certified, and proudly holds the TPN badge for top-tier content security.



Our transcription services

Machine-made transcription
Our automatic transcription creates a draft of your transcript in the audio’s language.
- Work faster: Quick and editable; ideal for reviews, rough drafts, or repurposing spoken content.
- Scale efficiently: Perfect for large volumes or tight budgets.
- Enhance your transcript: Built-in editor to refine, add speaker labels, and export in multiple formats (Word, TXT..).
- Stay secure & compliant: Files stored in Europe, GDPR compliant, and ISO certified (27001 & 9001).
90% accuracy
From €0.25/min (varies by language)
90+ languages

Human-made transcription
Our team of professionals creates >99% accurate transcripts, so you can focus on other projects.
- Unmatched accuracy: Professional transcribers deliver with over 99% accuracy. Perfect for legal, medical, academic, and other high-stakes content.
- Accessible & inclusive: Meeting accessibility standards like WCAG and ADA. Ideal for governments, and enterprises.
- Stay secure & compliant: Files stored in Europe, GDPR compliant, and ISO certified (27001 & 9001).
>99% accuracy
From €1.85/min (varies by language)
18+ languages
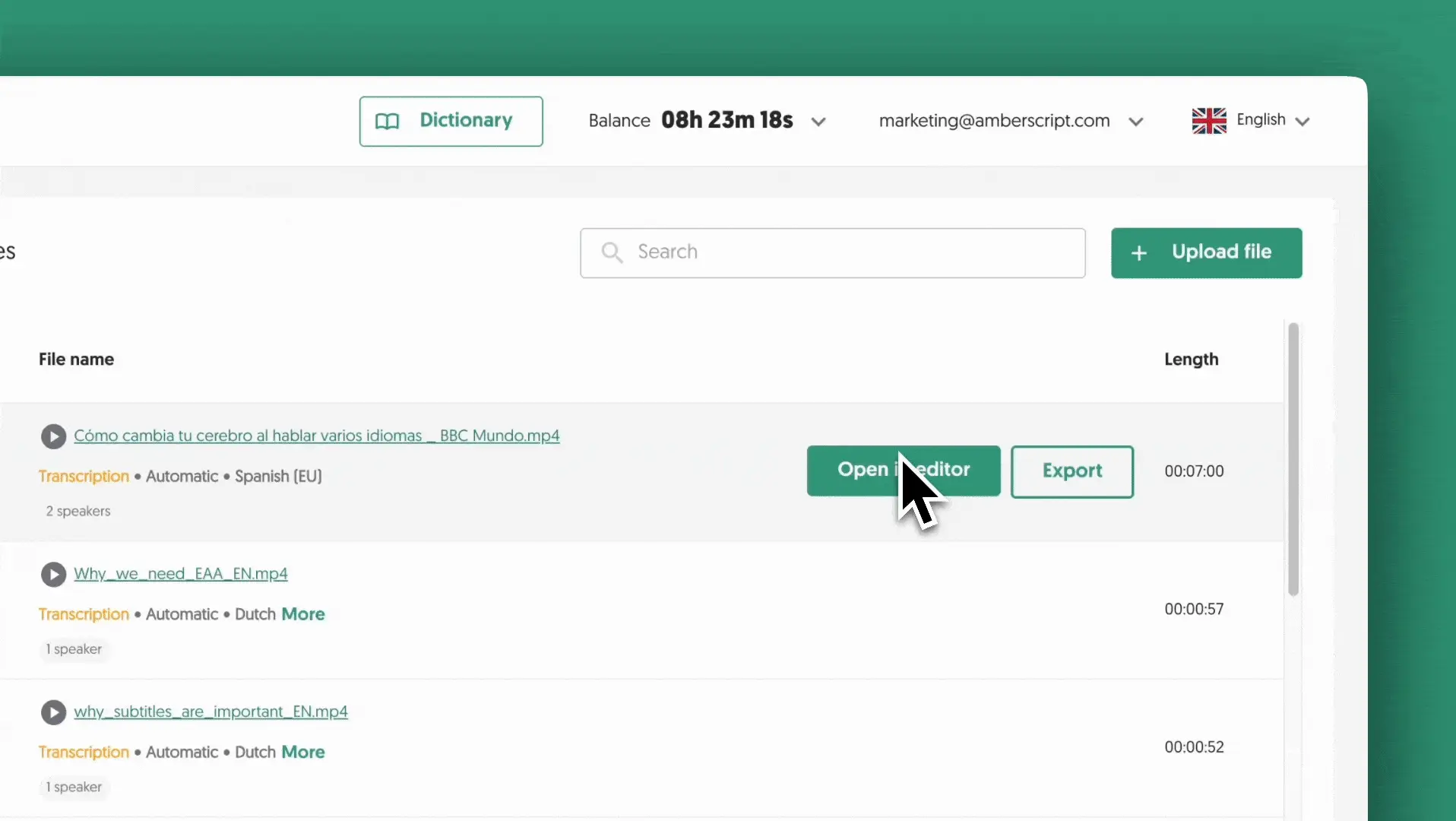
How it works
Meet our happy customers



Amberscript gave us fast, reliable transcripts that not only saved significant time but also strengthened the quality and efficiency of all our post-conference communications.

Adrián Román-López
Communications Officer, ICMPD
We got fast, high-quality service from Amberscript. Their data protection completely satisfies ethics requirements and keeps all interview information secure.

Rafa Martinez
Professor of Political Science at University of Barcelona

Thanks to Amberscript I could focus on my research, instead of doing the time-consuming task of transcribing. I’ve also experienced great and fast customer service, before and after the order with French-speaking support.

Audrey Rouyre
Ph.D. in Strategy and Research in Management at University of Montpellier

We got fast, high-quality service from Amberscript. Their data protection completely satisfies ethics requirements and keeps all interview information secure.

L. van den Berg
Lecturer-researcher at the Amsterdam University of Applied Sciences (HvA)
Languages and dialects
-
Afrikaans

-
Albanian

-
Amharic

-
Arabic

-
Armenian

-
Azerbaijani

-
Bahasa

-
Bashkir

-
Basque

-
Bengali (Bangladesh)

-
Bengali (India)

-
Bosnian
-
Burmese

-
Cantonese

-
Catalan
-
Chinese (Mandarin)

-
Croatian

-
Czech

-
Danish

-
Dutch

-
English (Australia)

-
English (United Kingdom)

-
English (United States)

-
English (all accents)
-
Esperanto

-
Estonian

-
Farsi (Iran

-
Filipino

-
Finnish

-
Flemish

-
French

-
French (Canada)

-
Galician
-
Georgian

-
German (Germany)

-
German (Austria)

-
German (Switzerland)

-
German (Swiss Mundart)
-
German (all accents)
-
Greek

-
Gujarati
-
Hebrew

-
Hindi
-
Hungarian

-
Icelandic

-
Italian

-
Japanese

-
Javanese
-
Kannada
-
Khmer

-
Korean

-
Lao

-
Latvian

-
Lithuanian

-
Macedonian

-
Malay

-
Malayalam
-
Maltese

-
Marathi
-
Mongolian

-
Nepali (Nepal)

-
Norwegian

-
Polish
-
Portuguese

-
Portuguese (Brazil)

-
Punjabi
-
Romanian

-
Russian

-
Serbian

-
Sinhala

-
Slovakian

-
Slovenian

-
Spanish
-
Spanish (LATAM)

-
Sundanese
-
Swahili (Kenya)

-
Swahili (Tanzania)

-
Swedish

-
Tamil (India)
-
Tamil (Malaysia)
-
Tamil (Singapore)

-
Tamil (Sri Lanka)
-
Telugu
-
Thai

-
Turkish

-
Ukrainian

-
Urdu (India)
-
Urdu (Pakistan)

-
Uyghur
-
Uzbek

-
Vietnamese

-
Welsh
-
Zulu
-
Bulgaria

-
Catalan
-
Danish
-
Dutch
-
Dutch (Belgium)
-
English (Australia)
-
English (US)
-
English (UK)
-
Finnish
-
French
-
French (Canada)
-
German
-
German (Austria)
-
German (Switzerland)
-
German (Swiss Mundart)
-
German (all accents)
-
Hungarian
-
Italian
-
Norwegian
-
Polish
-
Portuguese
-
Portuguese (Brazil)
-
Romanian
-
Russian
-
Spanish
-
Swedish
-
Turkish
-
Ukrainian
Interested in professional transcription services?
Want to become an Amberscript language expert?
Transcription solutions tailored to your needs
-


Universities & Education
Accurate transcripts enhance analysis, note‑taking, publishing, and accessibility for students.
-


Governments
For policymakers, public organizations, and NGOs. Empower citizens with equal access and make your content inclusive for everyone.
-


Legal
Accurate legal transcription delivers verbatim records for evidence and compliance.
-


Healthcare
Secure medical transcription ensures accurate record‑keeping, billing, referrals, and compliance (HIPAA).
-


Media & Broadcasting
Detailed transcripts and dialogue lists keep your post‑production workflow efficient and compliant.
-


Digital accessibility
Accurate transcripts support digital accessibility and help meet global accessibility standards.
-


Interviews
Transcribe audio interviews quickly and accurately.
-


Podcasts
Repurpose content, enhance SEO visibility, and expand your audience with podcast transcription.
-


Research
For faster analysis and easier reporting of research findings.
Transcription FAQs
/01
How long does it take until I receive a transcript?
Typically, machine-made transcripts are ready within minutes. Transcripts corrected by our professional transcribers are delivered within 5 working days. You can also place a rush order during the uploading process. Rush orders can be delivered within 1 business day.
/02
How can I edit my transcript?
The file will be delivered in your account on Amberscript, so the file can be opened in our online editor, where you can make some final corrections or changes if needed.
/03
Can you rush my order?
Yes, typically we can rush your order and deliver it within 1 business day. For us to be able to deliver the order within 1 business day:
- Your audio must be under 90 minutes
- You must upload it before 16:00
- Sound must be of a good quality
You can select rush delivery when uploading a file or ask for it when requesting a quote.
/04
In which formats can I export my transcript?
Our software allows you to export your transcript as a JSON, Word, VTT, SRT, EBU-STL or Text file.
/05
Do you provide full verbatim or clean read transcripts?
For the manual transcription service, we provide both transcription types. For automatic transcription, you can choose “Clean Read” feature, when exporting the file.
/06
How can I improve the accuracy of the transcript?
The accuracy can be improved by making sure your audio quality is very high. Want to know how to optimize your audio? Read it here! You can also order manual services, instead of automatic. Then our professional transcribers will make you transcript >99% accurate!
/07
Can you transcribe audio with foreign accents?
Yes, the language models we use are constantly being trained to pick up on accents and know how to understand foreign accents.
/08
Do you transcribe files with multiple speakers?
Yes, our software can transcribe multi-speaker files and can also distinguish different speakers in the transcript. Different speakers will be indicated as “speaker 1”, “speaker 2”, etc. You can rename speakers in the online editor.
Interested in business solutions?
Get volume discounts, tailored offers and dedicated project management:
Volume discounts
Access for multiple users
Centralized billing
Personalized onboarding
Integration of your workflow via API

