3 ways automated speech recognition (ASR) can foster digital inclusion

In the EU the directive on digital inclusion of the websites and mobile applications of public sector bodies’ (EU2016/2102) was put into place. This directive demands public organizations to become more inclusive by making all their openly published content accessible to people with disabilities. This group includes approximately 50 – 75 million citizens and represents 10-15% of the entire population of the 27 EU member states. What can Automated Speech Recognition do to help in that?
What is ASR?
Automated Speech Recognition (ASR) is a technology that enables computers to recognize and interpret spoken language. It involves converting spoken words into written text, which can then be analyzed, stored, and processed by machines. ASR is commonly used in voice assistants, transcription software, and speech-to-text tools.
What is digital inclusion?
Digital inclusion, on the other hand, refers to the process of ensuring that everyone, regardless of their background or circumstances, has equal access to digital technologies and services. This includes internet access, digital literacy, and the skills needed to use digital tools effectively.
How do these two concepts match?
ASR is relevant to digital inclusion because it has the potential to break down barriers and increase accessibility for people who may otherwise be excluded from digital technologies. By converting spoken words into written text, ASR can make digital content and services more accessible to people with hearing impairments, language barriers, or other disabilities.
The challenge of digital accessibility
The digital world has revolutionized the way we live, work and communicate. However, for millions of people with disabilities, accessing the digital realm is not always a straightforward task. Digital accessibility refers to the extent to which digital technology, including software, websites, and applications, is accessible to all individuals, regardless of their abilities. Despite progress in recent years, many websites and applications still present significant accessibility barriers for people with disabilities, hindering their participation in the digital society.
The problem of digital accessibility has far-reaching implications for individuals and society as a whole. For individuals with disabilities, it can limit their ability to access information, education, and employment opportunities, and reduce their overall quality of life. It also perpetuates a culture of exclusion, where people with disabilities are further marginalized and isolated from mainstream society.
Three ways ASR can foster digital inclusion
Automated Speech Recognition technology has the potential to break down barriers to digital inclusion and create a more accessible and inclusive digital world. Here are three ways that ASR can foster digital inclusion:
Improving accessibility for people with disabilities:
ASR technology can be an incredibly powerful tool for people who are deaf or hard of hearing, as well as those with limited mobility. By providing real-time captions or subtitles for audio and video content, ASR technology can make digital media more accessible to those who may have difficulty hearing or following along. Similarly, ASR-powered voice commands can allow people with limited mobility to control digital devices and access digital services more easily, empowering them to live more independently.
Enabling access for people with low literacy levels:
For people with low literacy levels, digital content and services can be incredibly difficult to access and navigate. However, ASR technology can help to bridge this gap by allowing users to interact with digital devices and services using their voice. This can be particularly helpful for people who struggle with reading or writing, allowing them to use the internet and access digital resources more easily.
Bridging the digital divide for non-native speakers:
In many regions and countries, the dominant language of the internet and digital services may not be the same as the primary language spoken by local residents. This can create a significant barrier to digital inclusion, as non-native speakers may struggle to access and understand digital content and services. However, ASR technology can help to bridge this divide by providing real-time translation and transcription services. By enabling users to interact with digital devices and services in their own language, ASR can empower non-native speakers to access digital resources and participate more fully in the digital world.
Case studies and examples
University Jena
In the case of the University of Jena, ASR technology was used to promote digital accessibility by making lectures and academic content more accessible to students with hearing impairments. The university used Amberscript’s ASR technology to automatically transcribe lectures and create captions for videos, making the content more accessible to students who may have difficulty following the spoken content.
This solution allowed students with hearing impairments to have equal access to academic content, enabling them to participate fully in lectures and discussions. It also helped to break down barriers to learning and promote inclusion within the university community.
By leveraging ASR technology, the University of Jena was able to improve digital accessibility and provide a more inclusive learning environment for all students.
Telecommunications corporation Orange
In this case study, ASR helped promote digital accessibility for a global audience by providing accurate and efficient transcription services. Orange, a global telecommunications company, needed to produce captions and transcripts for their digital content to make it accessible for people with hearing impairments or who speak different languages.
Using ASR technology provided by Amberscript, Orange was able to quickly and easily produce captions and transcripts for their content. This made their content more accessible and inclusive for a wider audience, including those who are deaf or hard of hearing, or those who speak different languages.
ASR technology also helped Orange save time and resources, as they were able to automate the transcription process and reduce the need for manual labor. This allowed Orange to produce content more efficiently and effectively, while still maintaining accuracy and quality.
Cheflix
ASR helped to promote digital accessibility in the partnership between Cheflix and Amberscript by providing accurate and efficient closed captioning for Cheflix’s cooking videos. The closed captions, generated through ASR technology, make the videos accessible to people who are deaf or hard of hearing, as well as those who prefer to watch videos with captions.
ASR technology also enables Cheflix to offer their content in multiple languages, making it accessible to a wider audience, regardless of their native language. This promotes digital inclusion by removing language barriers and allowing more people to access the content.
Additionally, the use of ASR technology in this partnership demonstrates how technology can be used to create more accessible and inclusive digital experiences, ultimately promoting greater inclusion and accessibility for all individuals in society.
Challenges with ASR
Automated Speech Recognition (ASR) has come a long way in recent years, but there are still several challenges and limitations that need to be addressed. Here are some of the key challenges and limitations:
- Accuracy: Despite advances in ASR technology, accuracy remains a significant challenge. ASR software can struggle to accurately transcribe speech in noisy environments or when there are multiple speakers. This can make it difficult for people who rely on ASR to access digital content or communicate with others.
- Dialects and accents: ASR can have difficulty recognizing different dialects and accents, particularly those that are less common. This can be a significant barrier for individuals who speak with non-standard accents or dialects.
- Limited language support: ASR software is often limited to specific languages or dialects, which can be a significant challenge for people who speak minority languages or dialects.
- Limited customization: ASR software may not be customizable for specific industries or use cases, which can limit its usefulness in certain contexts.
Amberscript: the best choice
Amberscript has several features that help address some of the challenges and limitations of ASR technology. Besides transcription and subtitling services, the company additionally offers audiodesciption, translations and dubbing.
- Multilingual support: Amberscript can transcribe audio in 39+ languages, which helps to address the language barrier challenge.
- Accuracy: Amberscript uses advanced algorithms to achieve high accuracy rates in speech-to-text transcription. Additionally, it offers an interactive editor for users to review and edit their transcriptions to further improve accuracy. For special occasions of specific accents and dialects, Ammberscript offers the a professional service that uses proofreading by native language speaking experts.
- Customization: Amberscript allows users to Integrate speech recognition capabilities into their software by using Amberscripts audio to text API. It is possible to connect to generic models or even collaborate with to create a customized speech recognition for your specific use-case. Users can also train the software on specific voices or accents, which can improve accuracy even further.
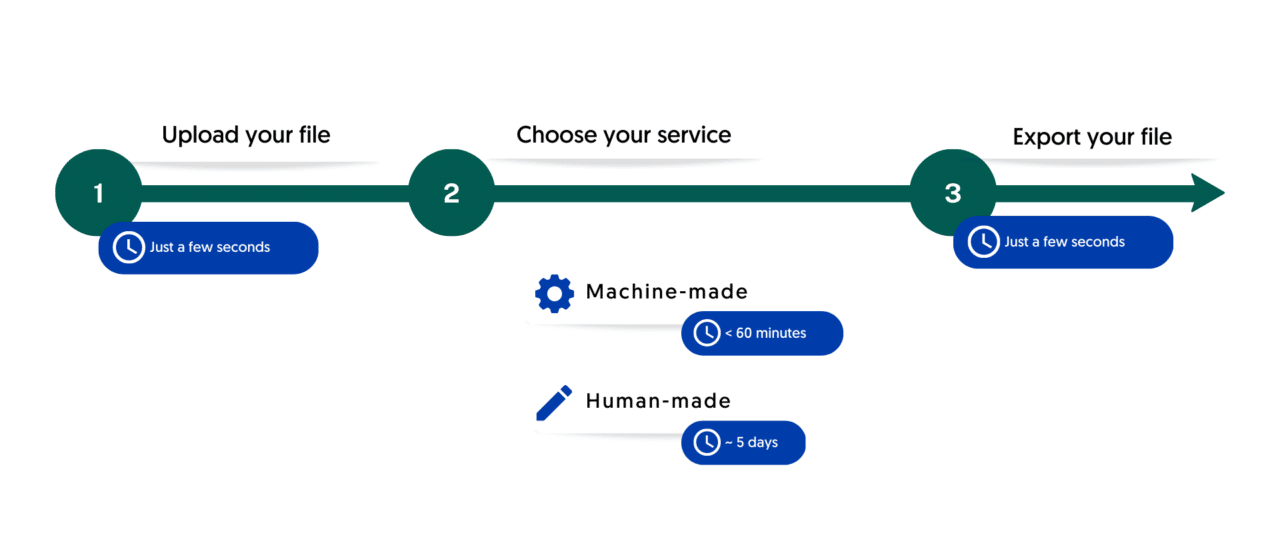
Transcriptions and subtitles with Amberscript in three simple steps
Accurate transcriptions in no time
Subtitling your conent has never been easier
Top reads
Accessibility in higher education: how universities can implement inclusive and compliant digital learning

Data protection in transcription software: what you need to know

Data sovereignty in transcription and subtitling: a strategic risk factor
